Update: Also check our follow up work N2M2: Neural Navigation for Mobile Manipulation.
Learning Kinematic Feasibility through
Reinforcement Learning
Daniel Honerkamp, Tim Welschehold, Abhinav Valada
Daniel Honerkamp, Tim Welschehold, Abhinav Valada
Mobile manipulation tasks remain one of the critical challenges for the widespread adoption of autonomous robots in both service and industrial scenarios. While planning approaches are good at generating feasible whole-body robot trajectories, they struggle with dynamic environments as well as the incorporation of constraints given by the task and the environment. On the other hand, dynamic motion models in the action space struggle with generating kinematically feasible trajectories for mobile manipulation actions. We propose a deep reinforcement learning approach to learn feasible dynamic motions for a mobile base while the end-effector follows a trajectory in task space generated by an arbitrary system to fulfill the task at hand. This modular formulation has several benefits: it enables us to readily transform a broad range of end-effector motions into mobile applications, it allows us to use the kinematic feasibility of the end-effector trajectory as a dense reward signal and its modular formulation allows it to generalise to unseen end-effector motions at test time. We demonstrate the capabilities of our approach on multiple mobile robot platforms with different kinematic abilities and different types of wheeled platforms in extensive simulated as well as real-world experiments.
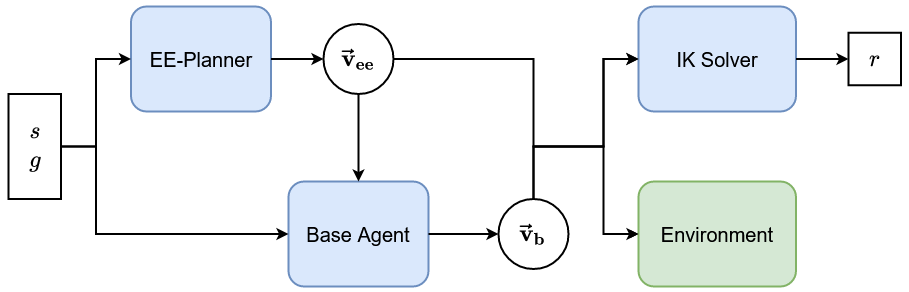
Mobile manipulation tasks require complex trajectories in the conjoint space of arm and base over long horizons. We decompose the problem into a given, arbitrary motion for the end-effector and a learned base policy. This allows us to readily transform end-effector motions into mobile applications and to strongly reduce the burden on the end-effector planner which can now be a reduced to a fairly simple system.
We then formulate this as a goal-conditional RL problem:
Given an end-effector motion dynamic, our goal is to ensure that the resulting EE-poses remain kinematically feasible at every time step.
Separating end-effector and base motions allows us directly leverage the kinematical feasibility of the EE-motions to train the base policy.
To evaluate the kinematic feasibility, we first compute the next desired end-effector pose from the current pose and velocities.
We then use standard kinematic solvers to evaluate whether this new pose is feasible and optimise this objective with recent model-free RL algorithms.
The simplicity and generality of the objective enables us to deploy the same approach across a variety of platforms without the need for expert based adaptions.
Finally we show that we can define a training task that enables us to learn base behaviours that generalise to completely unseen task motions in a zero-shot manner.
Daniel Honerkamp,
Tim Welschehold and
Abhinav Valada,
Learning Kinematic Feasibility through Deep Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2021.
Daniel Honerkamp,
Tim Welschehold and
Abhinav Valada,
N2M2: Learning Navigation for Arbitrary Mobile Manipulation Motions in Unseen and Dynamic
Environments
IEEE Transactions on Robotics, 2023.
This work was partly funded by the European Union’s Horizon 2020 research and innovation program under grant agreement No 871449-OpenDR and a research grant from the Eva Mayr-Stihl Stiftung.


